
:::info
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jinrui Yang, School of Computing & Information Systems, The University of Melbourne (Email: jinruiy@student.unimelb.edu.au);
(2) Timothy Baldwin, School of Computing & Information Systems, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence, UAE (Email: (tbaldwin,trevor.cohn)@unimelb.edu.au);
(3) Trevor Cohn, School of Computing & Information Systems, The University of Melbourne.
:::
Table of Links
Abstract and Intro
Background and Related Work
Multi-EuP
Experiments and Findings
Language Bias Discussion
Conclusion, Limitations, Ethics Statement, Acknowledgements, References, and Appendix
6 Conclusion
In this paper, we introduce Multi-EuP, a novel dataset for multilingual information retrieval across 24 languages, collected from European Parliament debates. The demographic information provided by the Multi-EuP dataset serves a dual purpose: not only does it contribute to multilingual retrieval tasks, but it also holds significant potential for advancing research in the realm of fairness and bias. This dataset can play a pivotal role in investigating issues of equitable representations and mitigation of biases within document ranking settings.
Multi-EuP facilitates diverse information retrieval (IR) scenarios, encompassing one-vs-one, one-vs-many, and many-vs-many settings. We demonstrated the utility of Multi-EuP as a benchmark for evaluating both monolingual and multilingual IR. Our study reveals the presence of language bias in multilingual IR when employing BM25. We further validate the effectiveness of mitigating this bias through the strategic implementation of whitespace as a language tokenizer.
We propose to conduct future work in three main areas. First, we intend to expand our investigation of language bias to encompass a broader range of ranking methods, including neural methods such as mDPR (Zhang et al., 2021), mColBERT (Lawrie et al., 2023) and PLAID-X(Santhanam et al., 2022). Second, we will expand the dataset by developing an automated API to retrieve data published by the European Parliament (EP), thereby ensuring realtime synchronization of our dataset. Lastly, our current experiments have explored language bias only, but we plan to further investigate gender bias, age bias, and nationality bias.
Limitations
The limitations of the Multi-EuP dataset are notable but navigable. Primarily, the temporal coverage of the dataset is confined to the past three years. This temporal constraint arises due to the fact that, preceding 2020, documents released by the EU were predominantly available in mono-lingual versions only. However, a potential remedy lies in the amalgamation of the Europarl (Koehn, 2005) collection, enabling a more comprehensive and holistic MultiEuP dataset.
Furthermore, it is worth noting the domain skew of the dataset, in that Multi-EuP inevitably centers on political matters. While this presents challenges, particularly in terms of the intricate nuances of political language, it inherently serves as an excellent foundational stepping stone for delving into the intricacies of multilingual retrieval. We believe, however, that this dataset can serve as a launching pad for broader explorations encompassing crossdomain and open-domain transfer learning scenarios, thus contributing to the broader landscape of language understanding and retrieval.
Ethics Statement
The dataset contains publicly-available EP data that does not include personal or sensitive information, with the exception of information relating to public officeholders, e.g., the names of the active members of the European Parliament, European Council, or other official administration bodies. The collected data is licensed under the Creative Commons Attribution 4.0 International licence. [8]
Acknowledgements
This research was funded by Melbourne Research Scholarship and undertaken using the LIEF HPCGPGPU Facility hosted at the University of Melbourne. This facility was established with the assistance of LIEF Grant LE170100200. We would like to thank George Buchanan for providing valuable feedback.
References
Luiz Henrique Bonifacio, Israel Campiotti, Roberto de Alencar Lotufo, and Rodrigo Frassetto Nogueira. 2021. mMARCO: A multilingual version of MS MARCO passage ranking dataset. CoRR, abs/2108.13897.
Ilias Chalkidis, Manos Fergadiotis, and Ion Androutsopoulos. 2021. MultiEURLEX – a multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6974–6996, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. 8
Jonathan H. Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. 2020. TyDi QA: A benchmark for information-seeking question answering in typologically diverse languages. Transactions of the Association for Computational Linguistics, 8:454–470.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for opendomain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over BERT. CoRR, abs/2004.12832.
Philipp Koehn. 2005. Europarl: A parallel corpus for statistical machine translation. In Proceedings of Machine Translation Summit X: Papers, pages 79–86, Phuket, Thailand.
Dawn Lawrie, Eugene Yang, Douglas W. Oard, and James Mayfield. 2023. Neural approaches to multilingual information retrieval. arXiv cs.IR 2209.01335.
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, JhengHong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A Python toolkit for reproducible information retrieval research with sparse and dense representations. castorini/pyserini.
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A human generated machine reading comprehension dataset. CoRR, abs/1611.09268.
Ella Rabinovich, Raj Nath Patel, Shachar Mirkin, Lucia Specia, and Shuly Wintner. 2017. Personalized machine translation: Preserving original author traits. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 1074–1084, Valencia, Spain. Association for Computational Linguistics.
Razieh Rahimi, Azadeh Shakery, and Irwin King. 2015. Multilingual information retrieval in the language modeling framework. Information Retrieval Journal, 18:246–281.
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. 2022. PLAID: An efficient engine for late interaction retrieval. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, CIKM ’22, page 1747–1756, New York, NY, USA. Association for Computing Machinery.
Jörg Tiedemann and Santhosh Thottingal. 2020. OPUSMT – building open translation services for the world. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, pages 479–480, Lisboa, Portugal. European Association for Machine Translation.
Eva Vanmassenhove and Christian Hardmeier. 2018. Europarl datasets with demographic speaker information. In Proceedings of the 21st Annual Conference of the European Association for Machine Translation, page 391, Alicante, Spain.
Denny Vrandeciˇ c and Markus Krötzsch. 2014. ´ Wikidata: A free collaborative knowledge base. Communications of the ACM, 57:78–85.
Konrad Wojtasik, Vadim Shishkin, Kacper Wołowiec, Arkadiusz Janz, and Maciej Piasecki. 2023. BEIRPL: Zero shot information retrieval benchmark for the Polish language. arXiv cs.IR 2305.19840.
Peilin Yang, Hui Fang, and Jimmy Lin. 2017. Anserini: Enabling the use of lucene for information retrieval research. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1253–1256.
Xinyu Zhang, Xueguang Ma, Peng Shi, and Jimmy Lin. 2021. Mr. TyDi: A multi-lingual benchmark for dense retrieval. arXiv cs.CL 2108.08787.
A. Appendix
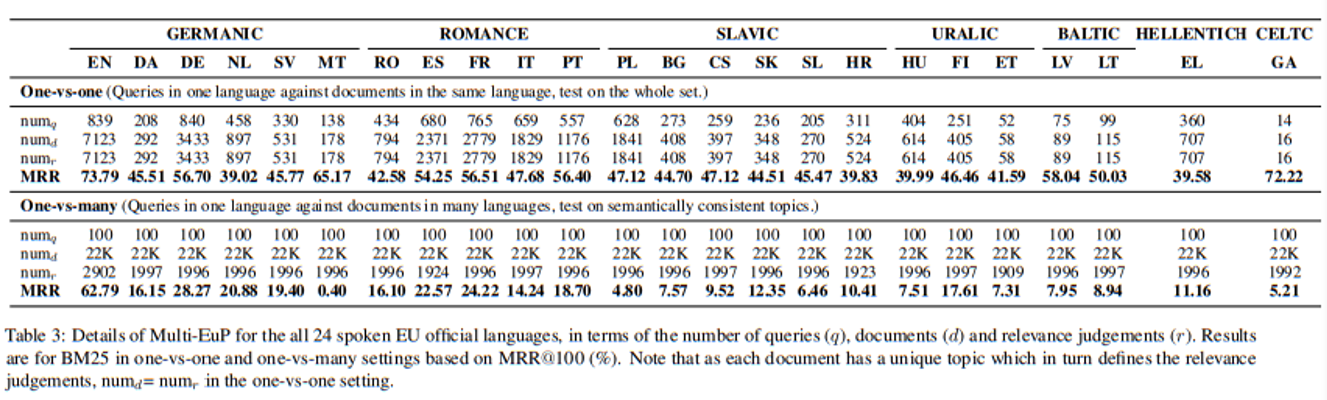
[8] ent/ legal-notice/legal-notice.html